9.1 A Gibbs Sampling Example: Comparing Two Poisson Means
Let’s revisit the problem of comparing the means from two independent Poisson samples. Counts {\(y_{Ai}\)} from the weekend days are assumed Poisson with mean \(\lambda_A\) and counts {\(y_{Bj}\)} from the weekday days are assumed Poisson with mean \(\lambda_B\). We are interested in learning about the ratio of means \[
\gamma=\frac{\lambda_B}{\lambda_A}.
\] We showed that the likelihood function in terms of the first Poisson mean \(\theta = \lambda_A\) and \(\gamma\) is given by \[
L(\theta, \gamma) = \exp(-n_A \theta) \theta^{s_A} \exp(-n_B (\theta\gamma)) (\theta\gamma)^{s_B}.
\] Assuming that \(\theta\) and \(\gamma\) are independent with \[
\theta \sim Gamma(a_0, b_0), \, \, \gamma \sim Gamma(a_g, b_g),
\] Then the posterior density of \((\theta, \gamma)\) is given, up to a proportionality constant, by \[\begin{eqnarray*}
g(\theta, \gamma | {\rm data}) & \propto & \exp(-n_A \theta) \theta^{s_A} \exp(-n_B (\theta\gamma)) (\theta\gamma)^{s_B} \nonumber \\
& \times & \theta^{a_0-1} \exp(-b_0 \theta) \gamma^{a_g-1} \exp(-b_g \gamma) \nonumber \\
\end{eqnarray*}\] By combining terms, we obtain the expression \[\begin{eqnarray*}
g(\theta, \gamma | {\rm data}) & \propto & \exp\left(-(b_0+n_A+n_B \gamma)\theta\right) \theta^{a_0+s_A+s_B-1} \nonumber \\
& \times & \exp(-b_g \gamma) \gamma^{a_g+s_B-1}. \nonumber \\
\end{eqnarray*}\]
Although this is a complicated joint density, the conditional posterior densities have familiar expressions. Suppose we fix a value of the first Poisson mean \(\theta\). Then the posterior density of \(\gamma\), conditional on \(\theta\), has the expression \[
g(\gamma | \theta, {\rm data}) \propto \exp(-(b_g + n_B \theta) \gamma) \gamma^{a_g+s_B-1},
\] which we recognize as a gamma density with shape \(a_g + s_B\) and rate \(b_g + n_B \theta\). Next, suppose we fix a value of the ratio of means \(\gamma\). Then the posterior of \(\theta\), conditional on \(\gamma\), has the form \[
g(\theta | \gamma, {\rm data}) \propto \exp\left(-(b_0+n_A+n_B \gamma)\theta\right) \theta^{a_0+s_A+s_B-1},
\] which is a gamma(\(a_0+s_A+s_B, b_0 + n_A + n_B \gamma\)) density.
Since the conditional posterior distributions are simple, this suggests the following Gibbs sampling algorithm.
Suppose the \(k\)th simulated values of the parameters are \((\gamma^{(k)}, \theta^{(k)})\). Then we simulate the next set of parameters by
[Step A:] simulating \(\gamma^{(k+1)}\) from a gamma(\(a_g + s_B, b_g + n_B \theta^{(k)}\)) distribution
[Step B:] simulating \(\theta^{(k+1)}\) from a gamma(\(a_0+s_A+s_B, b_0 + n_A + n_B \gamma^{(k+1)})\) distribution
In practice, one begins with a starting value for \(\theta\), say \(\theta^{0} = s_A/n_A\), and then iterate through \(m\) cycles of the Step A and Step B simulations, obtaining the simulated draws {\((\theta^{(j)}, \gamma^{(j)}), j = 1, ..., m\}\). Assuming a relatively short burn-in period, the complete set of simulated draws can be regarded as a sample from the joint posterior distribution of \(g(\theta, \gamma | y)\).
This algorithm is easy to program in R. Suppose theta is the current simulated draw of \(\theta\), and a0, b0, ag, bg are the prior parameters and s.A, n.A, s.B, n.B are the sample quantities. Then one cycle of Gibbs sampling is programmed by two applications of the rgamma() function.
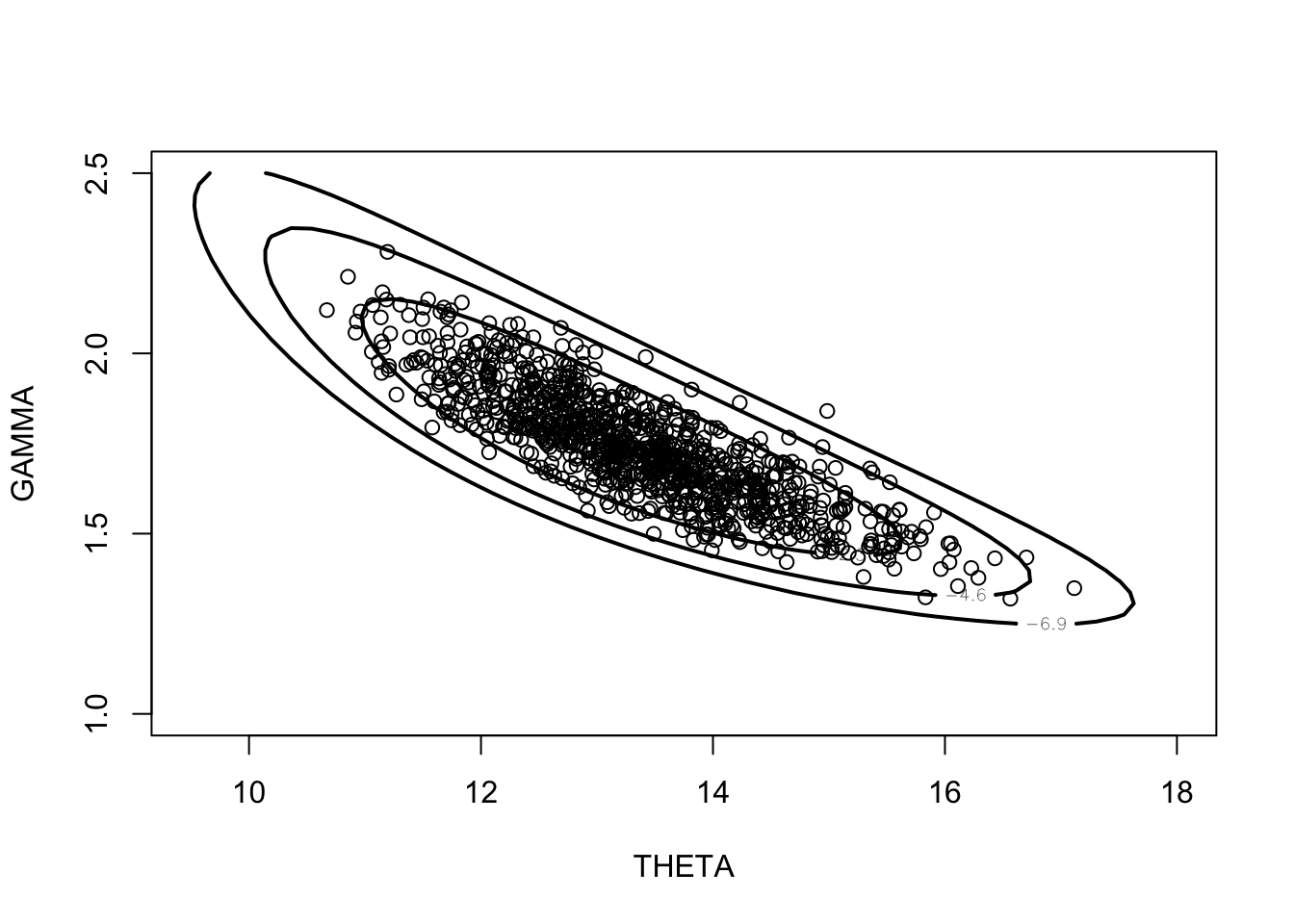
For the website hit data, the algorithm was started with the initial value \(\theta^{0} = s_A/n_A\) and run for 1000 cycles. Figure 1 displays a contour plot of the joint posterior density of \((\theta, \gamma)\) and the simulated sample is displayed. It appears that the Gibbs sampler draws are a reasonable approximation to the exact posterior.